-
[일본어]소설에 나오는 한자만 외우기 by Programming(Python, tiki, beautifulSoup, pandas) Anki취미 2019. 9. 10. 15:22
일본어를 배우는 것은 고통의 연속입니다.
특히 한자가 많은 사람들을 괴롭히죠.
JLPT N1을 가지고 있지만, 시험당시 어휘는 턱걸이고 공부를 안하다보니 한자만 보면 까막눈이 되버리더군요.
요즘 일본어로 된 소설을 잘 안 읽어서 이참에 한자도 외울겸 소설도 읽어보려 합니다.
소설은 평소에 읽고 있던 "책벌레의 하극상"을 가져올겁니다.
한자 사전은 네이버 사전,
한자 추출, 네이버 사전 크롤링은 python라이브러리 tiki와 beatifulSoup, requests
csv파일을 다루기 위해서 pandas도 사용합니다.
한자 암기는 Anki를 사용합니다.
결과물

일어소설가져오기
먼저 소설을 구해야합니다.
저는 PDF로 구했습니다.
小説家になろう - みんなのための小説投稿サイト
転生大聖女、実力を隠して錬金術学科に入学する ~モフモフに愛された令嬢は、モフモ… 白石 新 異世界恋愛
syosetu.com
"소설가가 되자"라는 사이트에서 인터넷 소설을 쉽게 구하실 수 있습니다.
개발환경
그럼 PDF가 준비 되었고 다음은 프로그램입니다.
- python3
- beatifulSoup4
- tiki
- requests
- lxml
- pandas
- java
등의 프로그램 및 파이썬 라이브러리가 깔려 있어야합니다
IDE(통합개발환경)은 저는 파이참을 사용하겠습니다.

파이참을 사용하면 Settings-Project Interpreter에서 위에 상기된 라이브러리를 쉽게 설치할 수 있습니다. PDF파싱
준비가 되었으면 이제 코딩을 시작합니다.
먼저 PDF에서 글자를 긁어모아야합니다.
PDFPaser.py를 만듭니다.
#PDFPaser.py from tika import parser #PDF에서 글자 추출 def PDF2String(fileName): rawText = parser.from_file(fileName) # rawList = rawText['content'].splitlines() return rawText #테스트 if __name__ == '__main__': text = PDF2String('N4830BU.pdf') print(text)우리가 원하는건 단순히 PDF에서 모든 글자를 뽑아오는 겁니다.
'N4830BU.pdf'에서 글자를 뽑아옵니다.
위 프로그램의 결과는 다음과 같습니다.

모든 글자가 뽑히긴 했는데 "\n"이나 히라가나, 가타카나는 관심시가 아니니 제거를 해주겠습니다.
먼저 PDF에서 한자를 뽑는 함수인 PDF2String(filename)은 이미 만들었고 모듈화를 위해 main.py를 따로 만들겠습니다.

main.py를 새로 만들어서 PDFPaser모듈을 사용합니다. PDFPaser.py는 앞으로 모듈로 사용할 것이고, main.py에서 프로그램의 흐름을 코딩할겁니다.
# main.py import PDFPaser text = PDFPaser.PDF2String('N4830BU.pdf') kanji_list = [char for char in text['content'] if ord(char) >= 0x4e00 and ord(char) <=0x9faf] #한자 리스트 print(kanji_list) #한자 갯수 print('length of kanji_list : '+len(kanji_list))유니코드로 0x4e00~0x9faf까지가 일본한자이기 때문에, if문으로 한자를 걸러줍니다.
코드 한줄이면 모든 text에서 한자만 걸러냅니다.(파이썬은 대단합니다)
결과는 다음과 같습니다.

이 소설에서 나오는 한자 갯수가 1450162개나 됩니다 한자만 잘 뽑혔지만, 갯수가 터무니 없이 많습니다. 중복되는 한자가 많네요.
중복되는 한자도 지워봅시다.
# main.py import PDFPaser text = PDFPaser.PDF2String('N4830BU.pdf') kanji_list = [char for char in text['content'] if ord(char) >= 0x4e00 and ord(char) <=0x9faf] #한자 리스트 print(kanji_list) #한자 갯수 print('length of kanji_list : '+str(len(kanji_list))) #중복제거 kanji_set = set(kanji_list) #한자 갯수 print('length of kanji_set : '+str(len(kanji_set)))
2596개의 한자가 나옵니다. list로 되어있는 한자를 단순히 set으로 바꾸는 것으로 중복되는 한자들이 지워집니다.
이제 이 한자들을 사전에 검색해야합니다.
사전은 네이버 일본어 사전을 사용하고, 이를 위해 크롤러를 만들필요가 있습니다.
네이버 일본어 사전 크롤러
크롤러를 만들기 위해서는 대상 페이지의 주소체계와 html 구조를 알아야합니다.
네이버일본어 사전에서 検을 검색합니다.
https://ja.dict.naver.com/search.nhn?range=all&q=%E6%A4%9C&sm=jpd_hty
'検': 네이버 일본어사전 검색결과
ja.dict.naver.com
그러면 주소창은 다음과 같습니다
"https://ja.dict.naver.com/search.nhn?range=all&q={한자}&sm=jpd_hty"
즉, 위 주소에서 {한자}에 해당하는 곳에 원하는 검색어를 넣으면, 검색창에 원하는 검색어를 넣는것과 동일합니다.
앞으로 이 링크와 검색어를 조합하여 페이지를 로드할겁니다.
Crawler.py를 만들고 다음과 같이 코딩합니다.
#Crawler.py from bs4 import BeautifulSoup import requests def search_link(kanji): return 'https://ja.dict.naver.com/search.nhn?range=all&q='+kanji def crawl(kanji): html = requests.get(search_link(kanji)) html.encoding = 'UTF-8'search_link에 넣는 kanji가 검색어 입니다. requests 라이브러리를 사용하여 해당 링크의 html을 받아오고 이를 utf-8로 인코딩합니다.
다음은 html 구조를 파악하는 일입니다.

検을 검색하였을 때 나오는 페이지(좌측)와 HTML구조(우측) F12를 누르면 html구조에서 検에 대한 정보가 어디있는지 찾을 수 있습니다.
훈독인 しらべる의 셀럭터는
#content > div.section.all.section_word > div:nth-child(2) > dl:nth-child(2) > dd:nth-child(4) > span
입니다.
우측 Element창에서 HTML태그를 선택하고 오른쪽 클릭-copy-copy selector로 쉽게 얻을 수 있습니다.
이제 프로그램을 짤 차례입니다.
#Crawler.py from bs4 import BeautifulSoup import requests def search_link(kanji): return 'https://ja.dict.naver.com/search.nhn?range=all&q='+kanji def crawl(kanji): html = requests.get(search_link(kanji)) html.encoding = 'UTF-8' # html 파싱 soup = BeautifulSoup(html.text, 'lxml') # 음독 um = soup.select('#content > div.section.all.section_word > div:nth-child(2) > dl:nth-child(2) > dd:nth-child(2)') # 훈독 hun = soup.select('#content > div.section.all.section_word > div:nth-child(2) > dl:nth-child(2) > dd:nth-child(4)') # 뜻 mean = soup.select( '#content > div.section.all.section_word > div:nth-child(2) > dl.top_dn.top_dn_v2 > dd.ft_col3 > span.ft_col3') try: um = ''.join(um[0].text.split()) except Exception: um = '' try: hun = ''.join(hun[0].text.split()) except: hun = '' try: mean = mean[0].text except: mean = '' kanjiData = {'kanji': kanji, 'um':um, 'hun': hun, 'mean':mean} return kanjiDataBeautifulSoup을 이용하여 html을 파싱합니다. 음독, 훈독, 뜻에 해당하는 selector로 쉽게 가져올 수 있습니다.
그리고 한자, 음독,훈독,뜻을 합쳐서 kanjiData를 만들고 반환합니다. 이렇게 하면 한 검색어(kanji)에 대하여 검색된 데이터가 반환됩니다.
이제 main.py에 적용해봅시다.
# main.py import PDFPaser import Crawler text = PDFPaser.PDF2String('N4830BU.pdf') kanji_list = [char for char in text['content'] if ord(char) >= 0x4e00 and ord(char) <=0x9faf] #한자 리스트 print(kanji_list) #한자 갯수 print('length of kanji_list : '+str(len(kanji_list))) #중복제거 kanji_set = set(kanji_list) #한자 갯수 print('length of kanji_set : '+str(len(kanji_set))) anki_data = list() #한자 크롤링 for kanji in kanji_set: data = Crawler.crawl(kanji) print(data['kanji']) print(data['um']) print(data['hun']) print(data['mean']) anki_data.append(data)한자 검색데이터가 저장될 anki_data라는 list에 크롤링한 데이터를 전부 집어 넣습니다.
결과적으로 for는 2596번 실행 될것이며 2596개의 data가 anki_data에 삽입될것입니다.

한자 검색중... 그런데 검색되는 한자들을 보면 아예 훈독, 음독, 뜻이 없는 경우가 존재합니다.
이러한 경우 해당 한자들을 검색해보면 앞서 본 検과는 다른 양식으로 검색이 됩니다.

음독, 훈독, 뜻이 존재하지 않음 따라서 한자가 검색되지 않는 경우는 일일이 찾아서 넣거나, 예외적으로 처리를 해주어야합니다.
하지만 이러한 경우는 소수이고 시간이 오래걸리는 작업이기 때문에 생략하도록 합니다.
이제 anki_data를 채워넣는것 까지 햇으니 csv로 출력하는 것 까지 해봅시다.
# main.py import PDFPaser import Crawler import pandas as pd text = PDFPaser.PDF2String('N4830BU.pdf') kanji_list = [char for char in text['content'] if ord(char) >= 0x4e00 and ord(char) <=0x9faf] #한자 리스트 print(kanji_list) #한자 갯수 print('length of kanji_list : '+str(len(kanji_list))) #중복제거 kanji_set = set(kanji_list) #한자 갯수 print('length of kanji_set : '+str(len(kanji_set))) anki_data = list() #한자 크롤링 for kanji in kanji_set: data = Crawler.crawl(kanji) print(data['kanji']) print(data['um']) print(data['hun']) print(data['mean']) anki_data.append(data) panda = pd.DataFrame(anki_data) panda.to_csv('anki.csv', mode='w')main에서 단순히 pandas를 import하고 밑에 두줄만 써주면 됩니다. 프로그램 실행이 종료되고 나면 'anki.csv'가 생성됩니다.
이 anki.csv를 메모장으로 실행하면 다음과 같이 크롤링된 데이터가 잘 보입니다.(Exel로 열 경우 인코딩이 맞지 않아 글자가 깨집니다. utf-8에서 EUC-KR(ANSI)로 변환을 해야합니다)

2596개의 한자들 ANKI에 CSV파일 추가하기
이제 anki에 데이터를 넣을 준비는 끝났습니다.
anki(암기 프로그램)에 이 csv를 넣어줍시다. 그 전에 anki부터 설치합니다.
Anki는 다음과 같은 사이트에서 설치가 가능합니다.
Anki - powerful, intelligent flashcards
Choose a platform from the left. Latest Version Download Anki for 64 bit Windows 7/8/10 (2.1.15-standard) Download Anki for 32 bit Windows 7/8/10 (2.1.15-alternate) If in doubt, choose the standard version, as most Windows installations are 64 bit these da
apps.ankiweb.net
anki를 설치하고 실행하면 다음과 같이 단어가 아무 것도 없는 것을 확인 할 수 있습니다.

여기에 csv를 넣어줘야합니다.
일반적인 단어의 경우 바로 넣어줘도 문제가 되지 않지만,
일본 한자의 경우 한자, 음독, 훈독, 뜻이라는 4개의 필드를 설정해야 하기 때문에 먼저
CRTL-SHIFT-N을 눌러 노트 유형을 추가해야합니다.

추가를 누르면 노트가 추가됩니다. 
노트의 유형은 기본으로, 이름은 한자로 정합니다. '한자'노트를 추가하고 나면 다음과 같이 한자 노트가 유형에 보이게 됩니다.
이제 이 한자 노트를 선택하고 필드를 눌러줍니다.
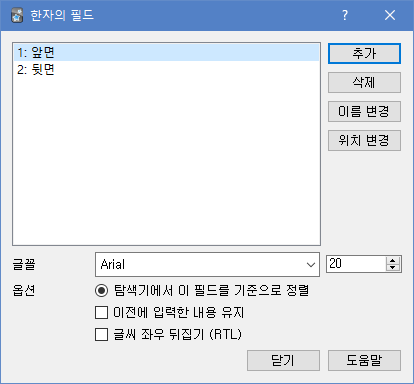
그럼 이렇게 앞면과 뒷면이 있습니다. 추가와 이름변경을 눌러서 다음과 같이 변경해줍시다.

이러면 필드는 끝났습니다. 다시 한자 노트를 서택하는 노트 유형으로 돌아가 필드 밑에 카드를 눌러줍니다.

그러면 다음과 같이 좌측에 앞면서식, 스타일, 뒷면 서식이 있습니다. 이 부분을 다음과 같이 변경해줍니다.

앞면 미리보기와 뒷면 미리보기가 위와 같이 나오는 것을 확인하고 닫기를 누르면 됩니다.
그러면 이제 csv에서 한자 데이터를 가져올 일만 남았습니다.
Anki 메인에서 파일가져오기를 선택합니다
하단 맨 우측- 파일가져오기 파일 선택창이 뜨는데 여기서 csv파일을 선택합니다.
그럼 다음과 같이 창이 뜹니다.

유형이 '한자'인것을 확인하고 필드1,2,3,4,5가 저렇게 뜨면 성공입니다.
바로 가져오기를 누르지 마시고 다음과 같이 바꿔줍시다.

필드1은 무시 필드2부터 한자, 음독, 훈독, 뜻으로 배정하고 가져오기를 누릅니다.

그러면 가져오기가 완료됩니다.
이제 anki에서 한자를 외울 수 있습니다.

끝
- python3